Use ChatGPT or Claude like never before
Run them hard, run them hot.
For professionals who'd happily spend more for deeper output. The only research platform that lets you decide how hard, how long, and how deep the AI goes.
Your $20/month subscription is great — until you hit the ceiling. Deep research queries are rate-limited. The AI runs for a few minutes, gives you one report in a chat window, and that's all you get.
What if you need $20 worth of compute on a single analysis? What if you want the AI to think for an hour, not five minutes? You can't. Their deep research has zero configuration — you press a button and hope for the best.
And the output lives inside a chat thread — try handing that to a client or a team.
Want to throw $5 at a quick scan? Or $100 at a serious deep dive? You decide how much horsepower goes into each project. No rate limits, no query caps, no ceilings.
Instead of one report in a chat window, you get organized output files — executive summaries, detailed analyses, comparison matrices, action plans. Download them, share them, hand them to your team.
Clone a completed project, refine the prompt, cherry-pick what to carry forward. Each run builds on the findings of the last — going deeper with every iteration instead of starting from scratch.
See it in action
Real screenshots from the dashboard. Full transparency on every project and every dollar spent.
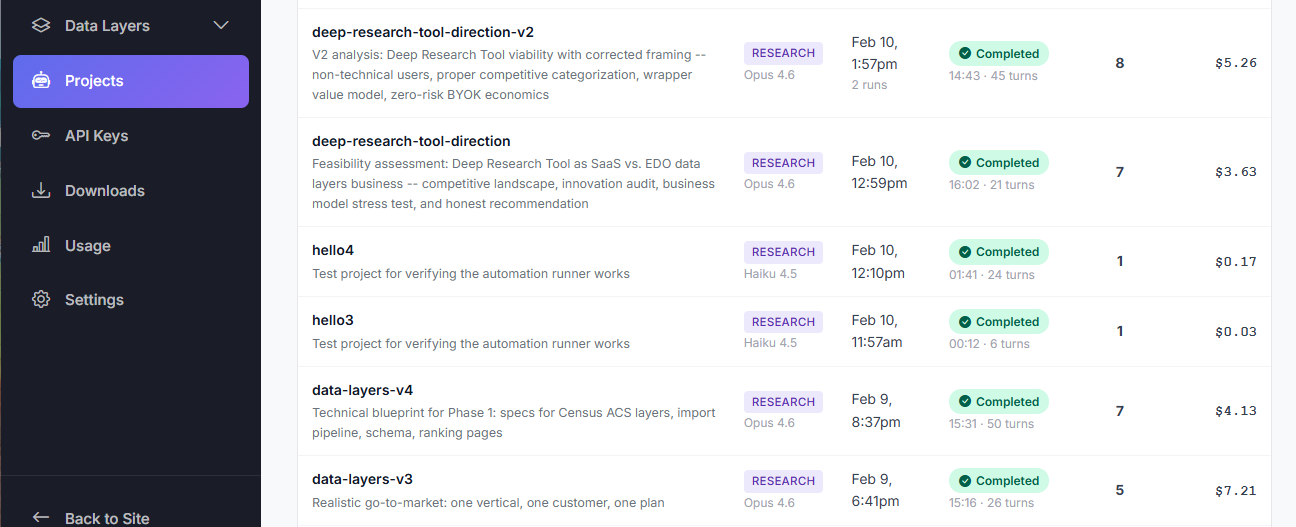
Your command center
Every project lives in one place — name, description, model, status, run count, and total cost at a glance. Clone any completed project to go deeper. This is what iterative research looks like.
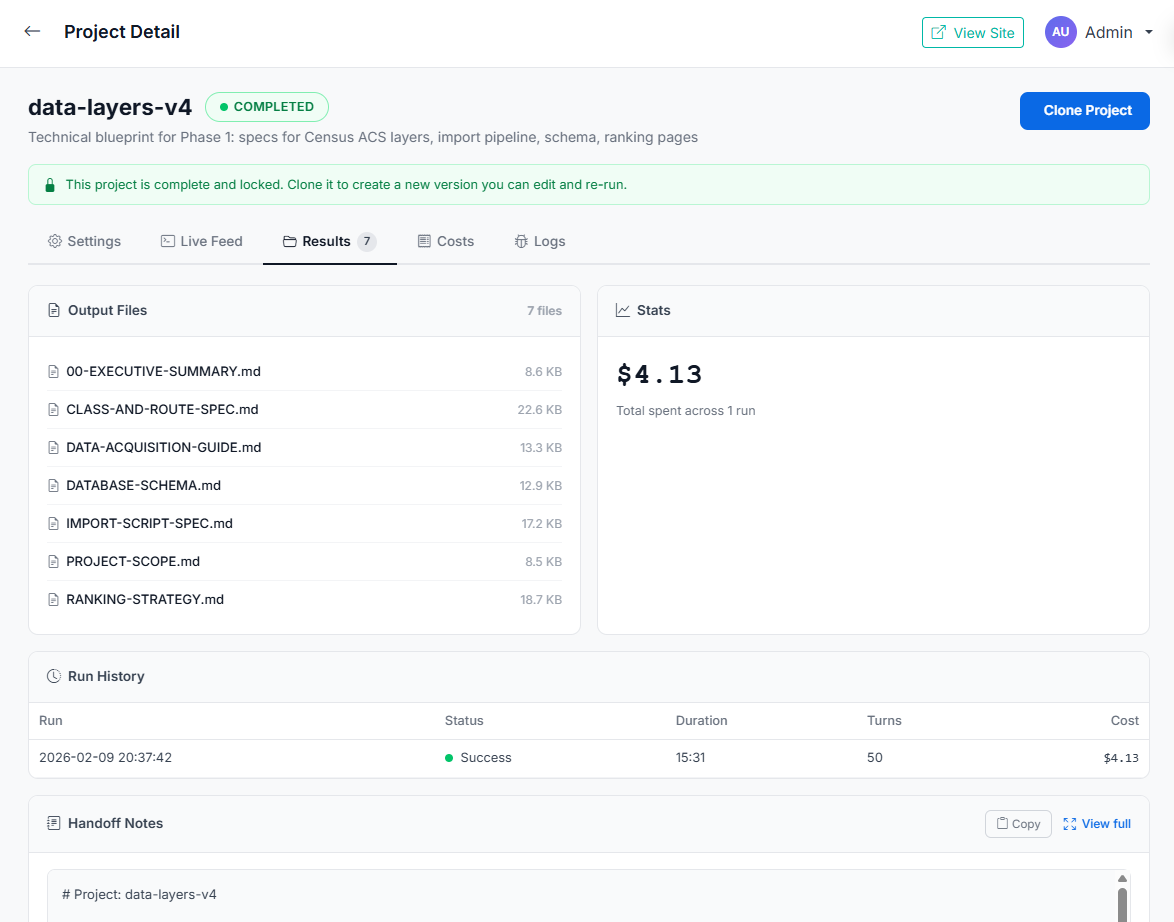
Structured, multi-file output
Every project produces organized deliverables — executive summaries, technical specs, strategy docs. Seven files totaling over 100KB of structured research from a single $4 run. View them in the built-in reader or download for your team.
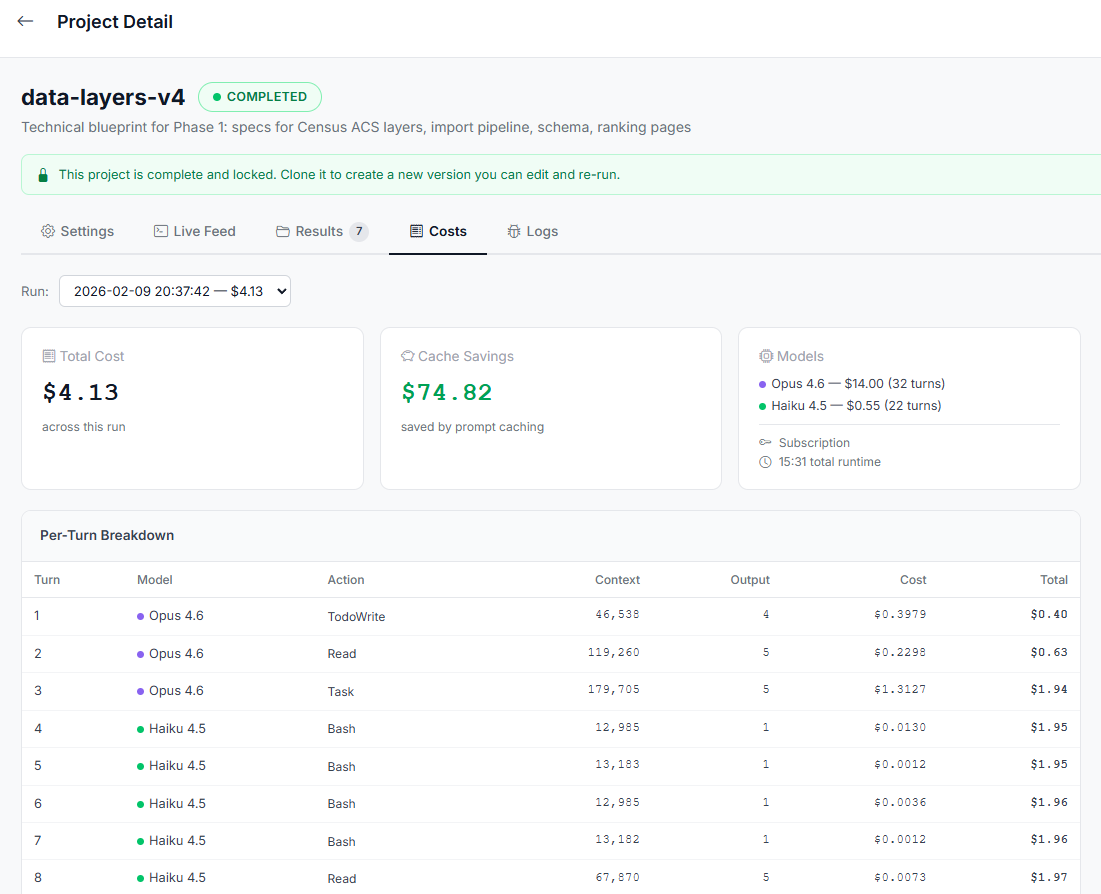
Every token accounted for
Full cost transparency down to the individual API turn. See exactly which model ran, how many tokens it consumed, and what it cost. Cache savings are tracked too — so you know what you're actually paying versus what you would have paid.
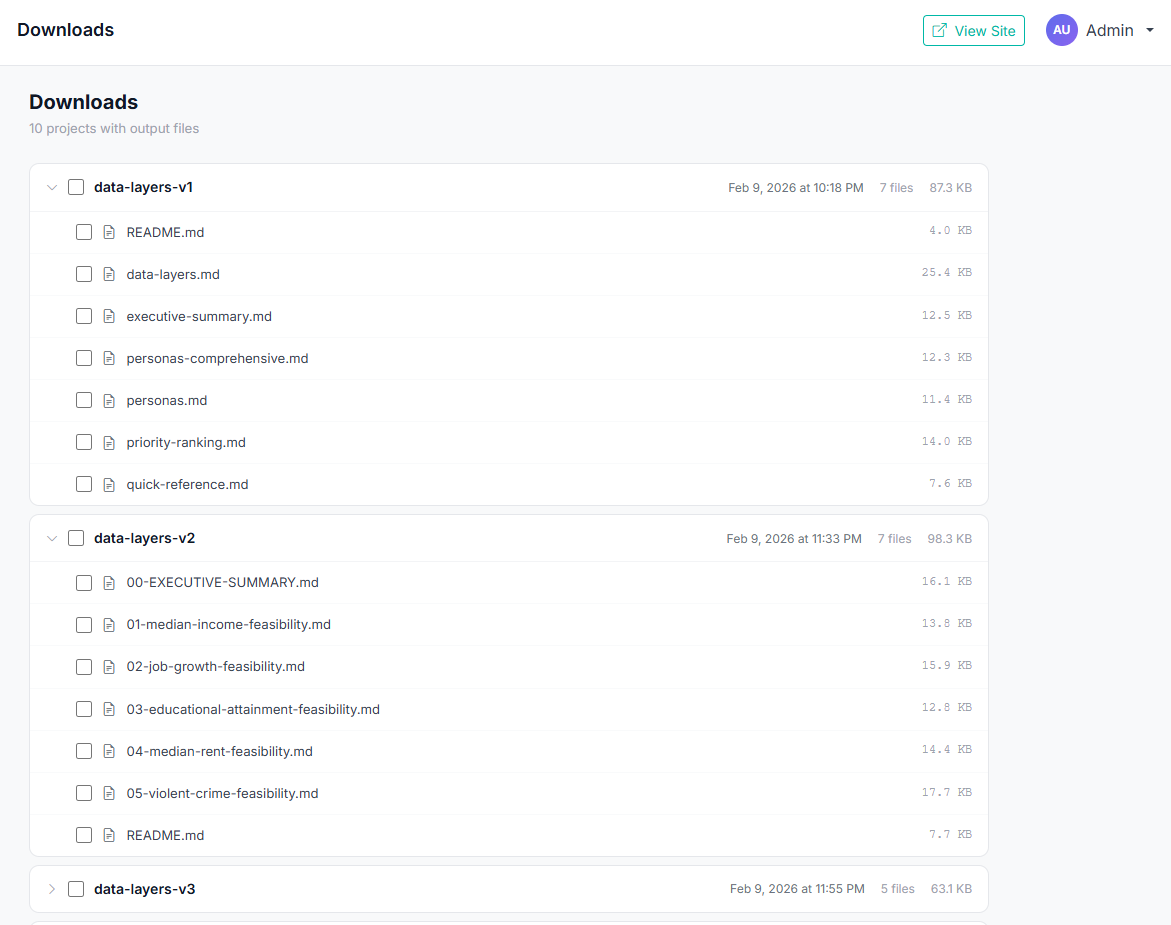
Download everything
All your output files organized by project and version. Select what you need, download individually or in bulk. Each iteration builds on the last — v1, v2, v3 — so you can see your research evolve over time.
Examples of people that use this system
Agency Consultant
Needs to deliver a 40-page competitive analysis by Monday. Runs three iterative sessions over the weekend — each one deeper than the last. Sends the final output straight to the client.
Market Researcher
Tracking emerging trends across dozens of industries. Sets up focused research sessions with specific output formats — market sizing, competitor grids, opportunity maps — and iterates weekly.
Investment Analyst
Due diligence on a potential acquisition. Needs the AI to dig through public filings, news, and industry data for hours — not minutes. Downloads the structured output and drops it into the deal memo.
Academic Researcher
Literature reviews that would take weeks done in a single deep session. Clones the project to explore adjacent topics, building a connected body of research across multiple runs.
Product Strategist
Exploring a new market before committing resources. Runs broad discovery first, then clones and narrows — pricing models, user personas, GTM strategies — all structured and downloadable.
Entrepreneur
Validating a new business idea before writing a single line of code. Runs deep sessions on market sizing, competitor landscape, and product-market fit — then clones the project to stress-test pricing models and go-to-market strategies.
How it works
Bring your API key
Bring your API key from any major LLM provider. They charge you directly for token usage at their standard rates. You save the API key in our dashboard. What you use is exactly what they charge you.
Describe your research & set the parameters
Describe your research topic in a detailed prompt — or use our helper tool to build one. Choose your favorite model, set cap limits for budget and max time the LLM can think on the matter. You can also define the output format.
Press Run — watch it work
We make the call to your favorite LLM. Based on the prompt and settings you choose, it could run for a few minutes or a few hours. Watch it live as it thinks in the dashboard with streaming output and full transparency. All costs are logged so you can review them as well.
Amazing Output
Receive organized, multi-file output — executive summaries, analysis documents, recommendations. Read them in the built-in viewer or download for your team.
The Real Sauce
Your first project is just the beginning. Clone it, refine the prompt, and take it a step further. Select past projects as references to go in a new direction while building on previous knowledge. Our scaffolding system lets you delve incredibly deep into any topic — something that would take a professional research agency weeks.
No subscription. No commitment.
You pay your LLM provider directly. We just take a small cut for running the infrastructure.
First $20 free
Your Delvantic balance starts at zero. We don't charge anything until your 5% usage fees accrue past $20. No credit card required to start.
5% usage fee
We calculate 5% of whatever you spend with your LLM provider. That's it. You spend $10 on tokens, we log $0.50. Fully transparent in your dashboard.
Pay when you're ready
Once your balance hits $20, replenish your account to keep going. No auto-billing, no surprises. You decide when and if you continue.
See what the engine built
We pointed this engine at a single project and let it run. It built a 3D city.
So powerful it created an entire world.
The same engine that runs your research built a living 3D city — permanent plaques, AI characters, bounties, and a citizen-governed economy. It's called Delvantic.
Enter the City →A core so powerful, projects are a side effect.
Our Projects
One domain, compounding synergy. Every project makes the core stronger.
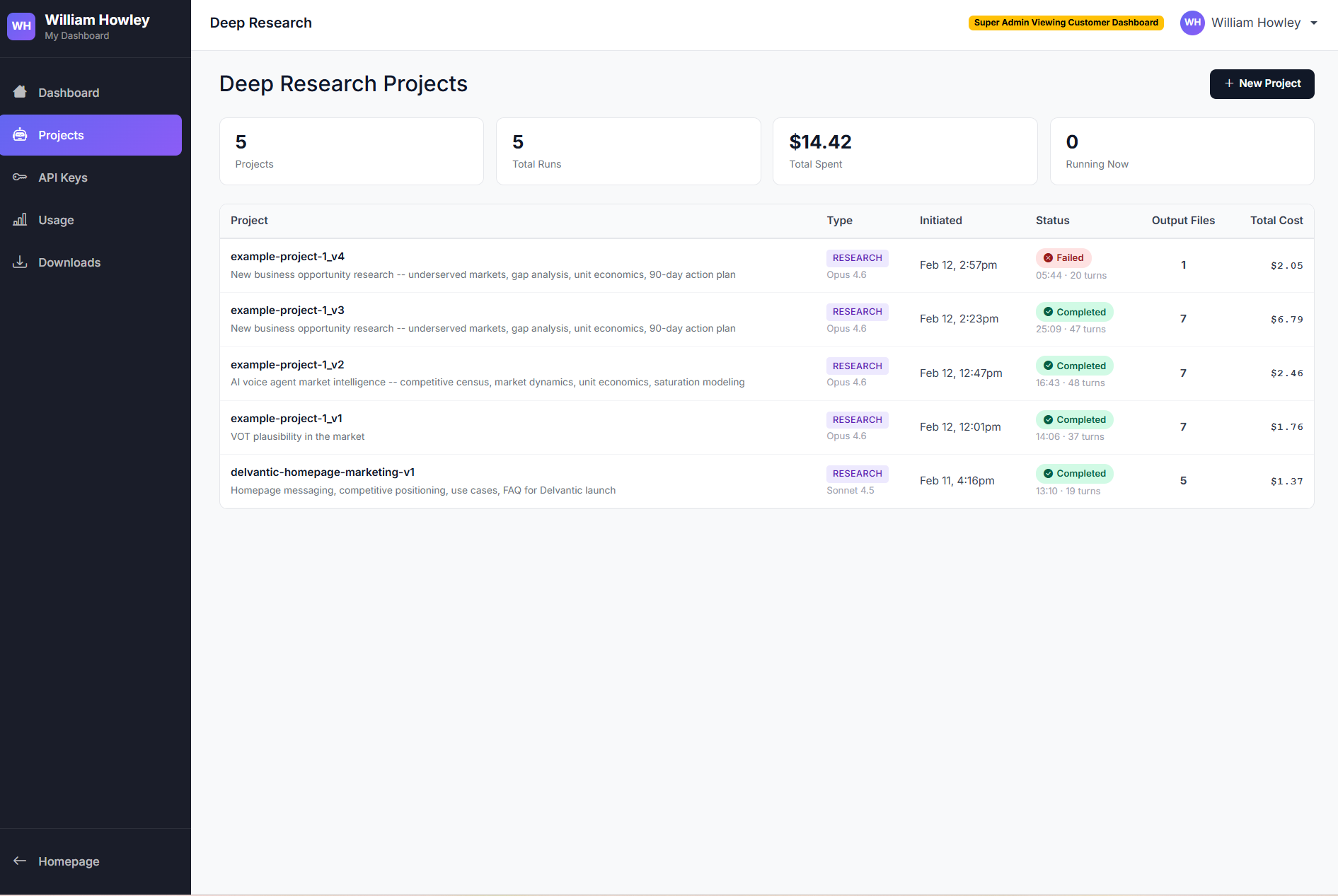
Deep Research
A deep research engine that became a masterclass in making AI perform. The foundation everything else is built on.
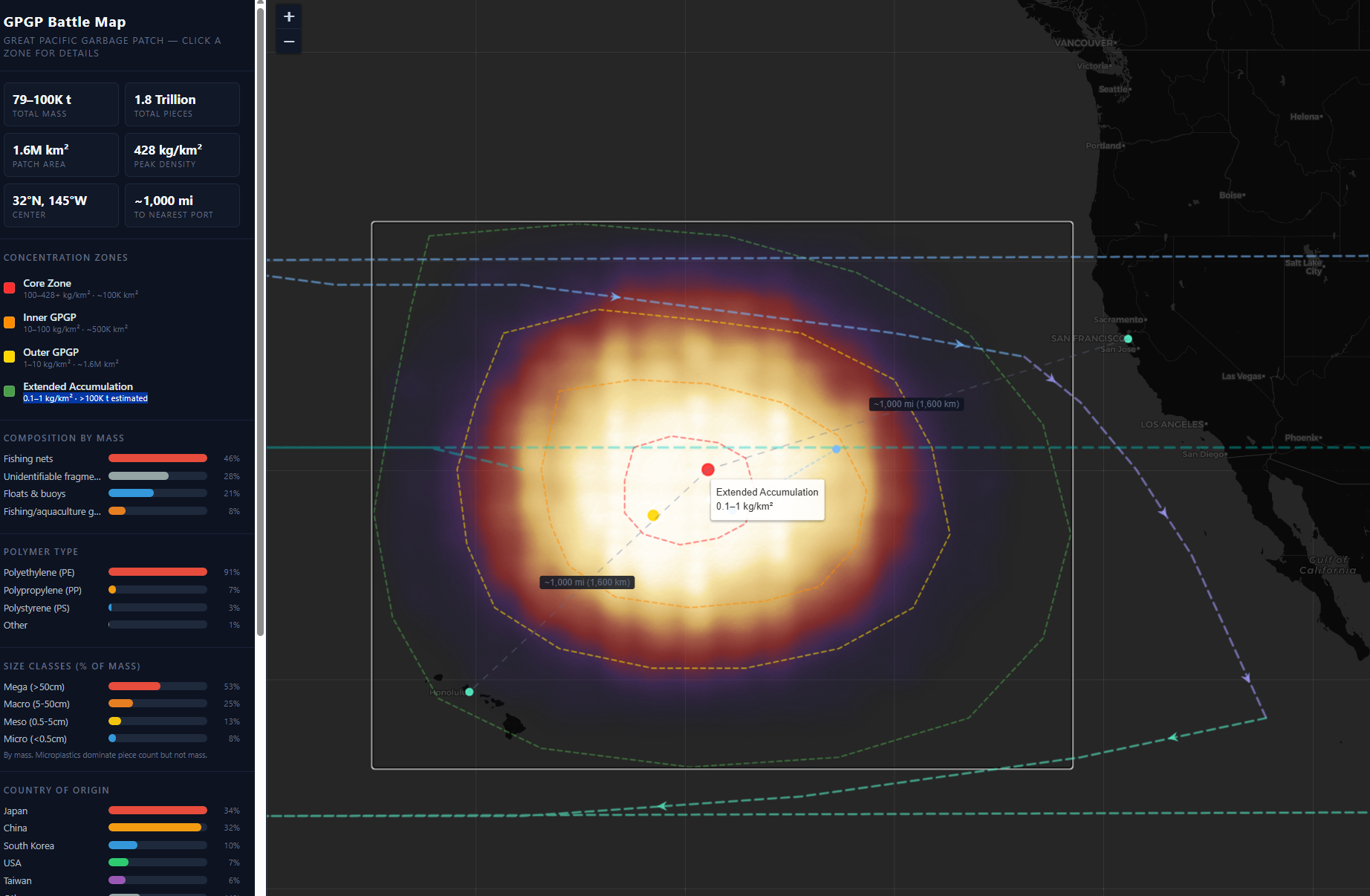
The Claw
Tackling a 1,400-mile trash island in the Pacific. AI-powered research into plasma gasification at sea.

Delvantic City
A 3D city in the browser where humans and AI build together. Permanent architecture, named creators, and an AI council.
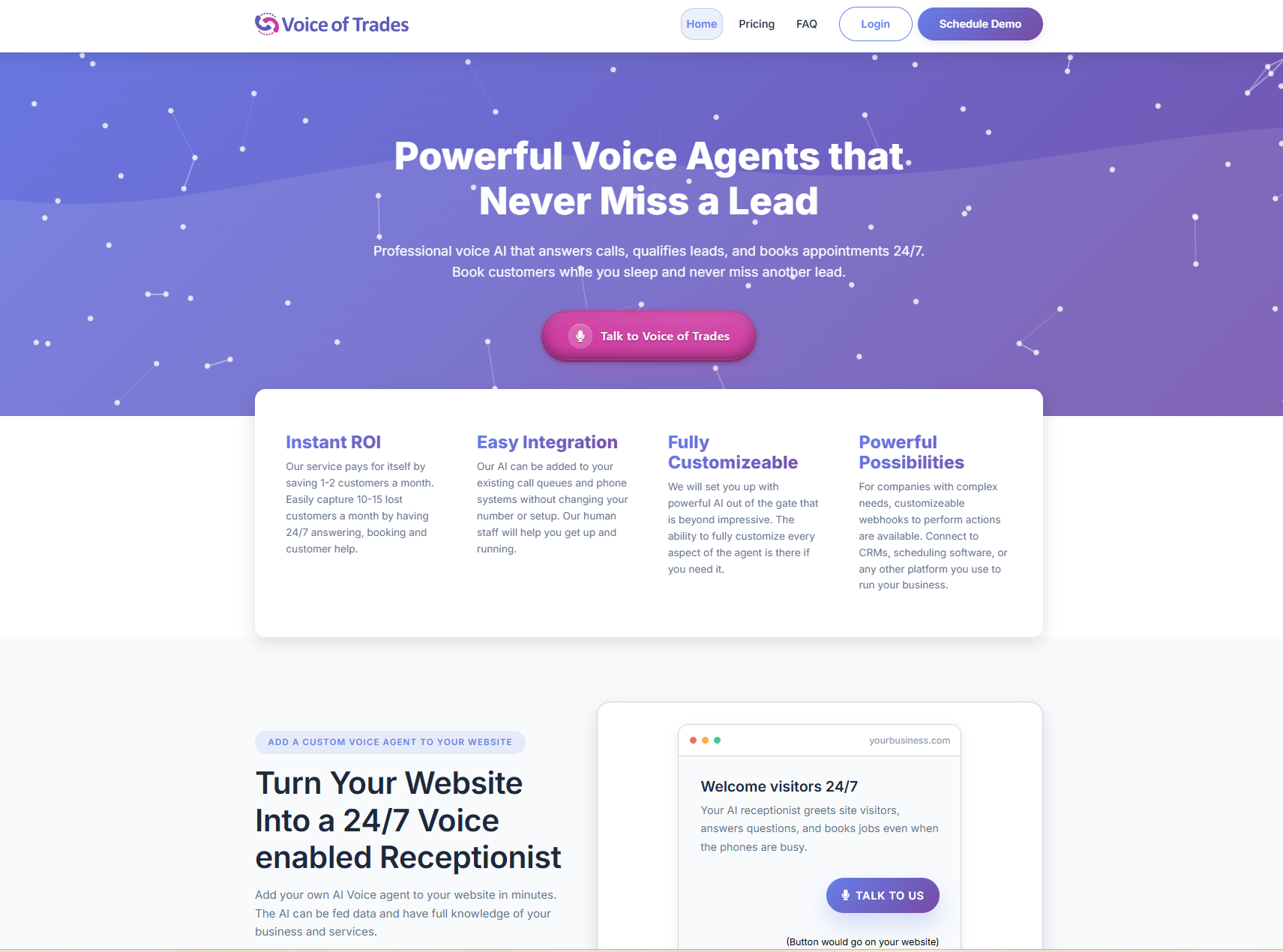
VoiceOfTrades.ai
AI voice answering and dispatching with calendar booking. Built for the trades, works for any business.
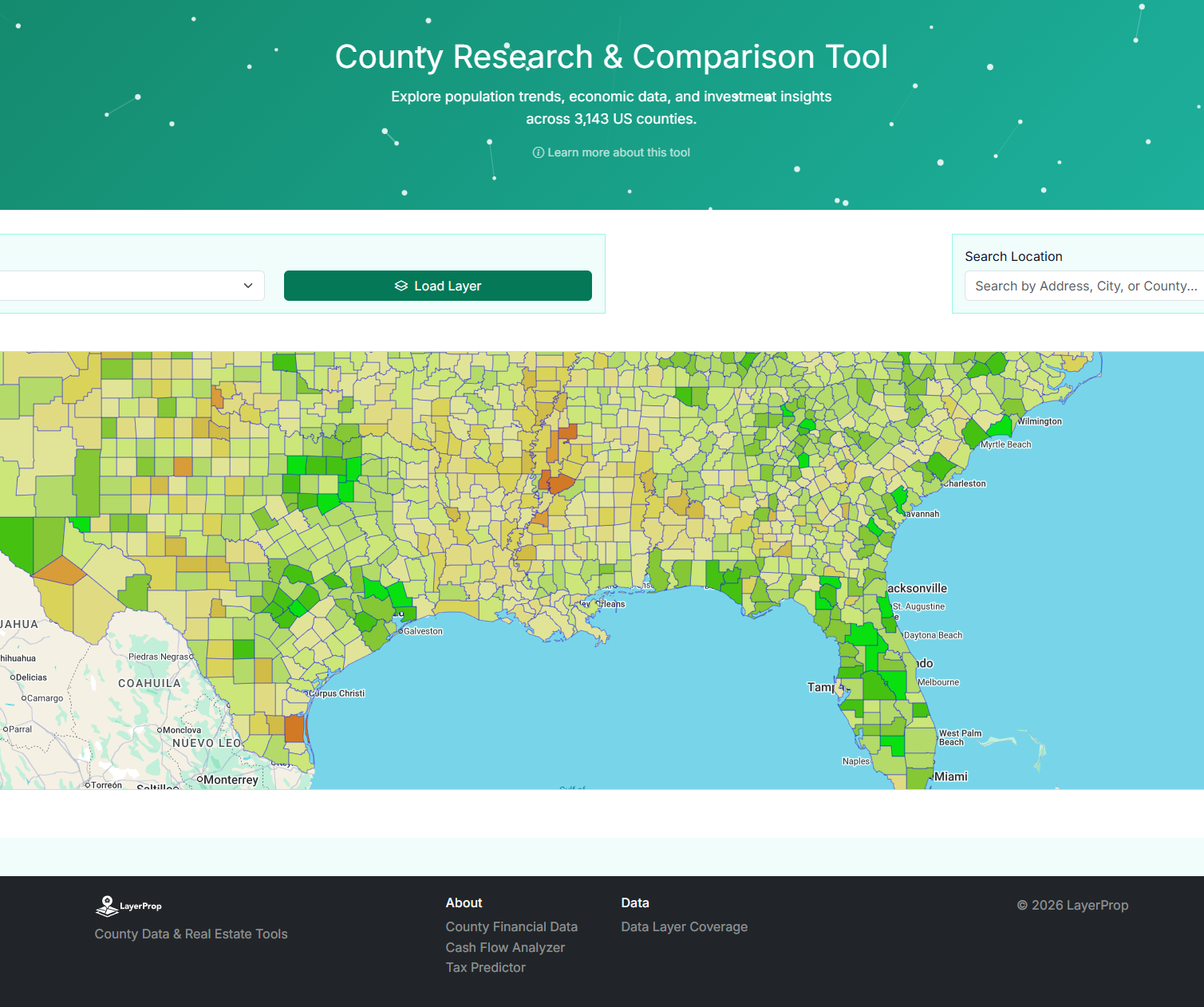
Layerprop.com
Mass data gathering engine powering an interactive County Comparator Map. 3,200 counties, 30 data sets.

AutoPilotSTR.com
Short-term rental property management. Expensing, cleaner management, owner dashboards, and operational tools.
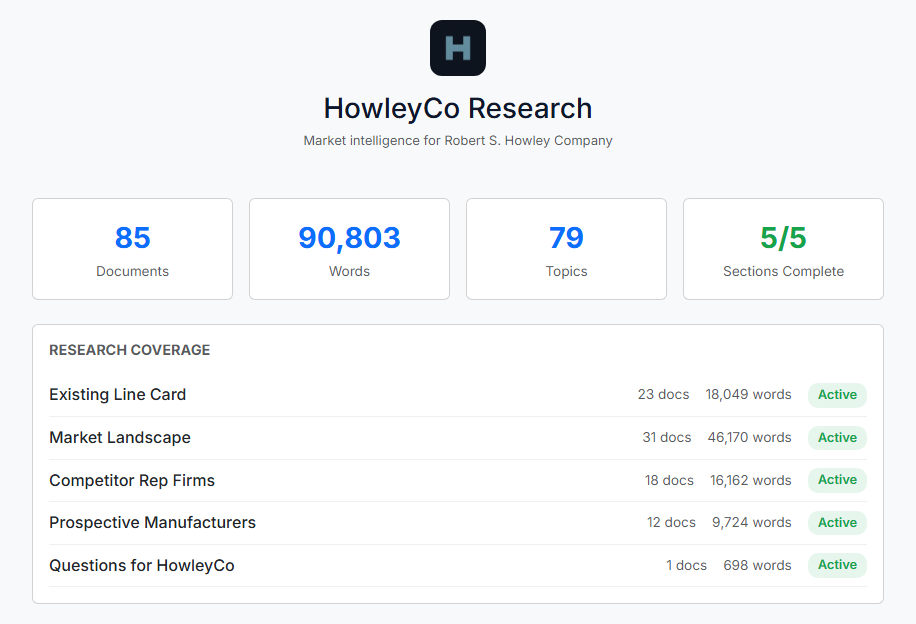
Electric
Research intelligence with hierarchical knowledge trees, depth scoring, competitive mapping, and territory analysis. Powering live market strategy for HowleyCo — invite-only.